
Introduction
RoPE1 is the most common positional embedding method that has been applied in many popular Language Models. RoPE has several properties, among which the long-term decay property is really interesting. Recently, I've been researching on how to make long-term decay property more customizable and controllable. Therefore, I want to get myself really understand why RoPE has the long-term decay property and how it works. In this post, I try to provide a more intuitive understanding of the long-term decay property of RoPE, and will also cover some recent researches relevant to RoPE.
Review | Some Details
Before getting the proof, let's first recal the Long-term decay of RoPE (Sec.3.4.3) in the original paper1. Contents below are completely copied from the orginal paper, the equation number from paper is kept.
We can group entries of vectors and in pairs, and the inner product of RoPE in Equation (16) can be written as a complex number multiplication.
where represents the to entries of . Denote and , and let and , we can rewrite the summation using Abel transformation
Thus,
Note that the value of decay with the relative distance increases by setting , as shown in Figure (2).
I believe some readers will have common questions with me, it seems in this part of paper, many details are elliminated for simplicity. I don't want to be the guy who just pretend these details are not important, focus on ideas, I will present more derivations here, since so far I haven't seen any detailed explanations here, including the blog of the author2.
Let's revise some annotation here. is the following matrix:
belongs to , where 10000 is called "base", as a predefined constant. The value of base will have interesting effect on RoPE, which we will discuss later.
is the d-dimensional word embedding vector of token (Let be a sequence of input tokens with being the element. The corresponding word embedding of is denoted as ). and are of the shape as .
Derivation of Eq.(35)
Now let's first derive Eq.(35). We first try to get its complete form without using complex numbers. Each block in matrix is a rotation matrix, where means contrarotating , while
which means rotate clockwise. Therefore, the LHS of Eq.(35) can be written as:
It's easy to see that the RHS of Eq.(4) is a scalar. We focus on first. For index , It's easy to see that elements in will only interact with the block , and we have:
And these two elements will be multiplied with the elements of , then we finally get:
Then we back to the complex number form used by authors. In Eq.(35), it's said is operated as complex multiplication, which means:
(Please don't confuse your self with the index and representing imaginary number). Then if we multiply the RHS of Eq.(5) with , and focus on real part, we will magically get the Eq.(key), with substituted by . It's quite elegant!
We then sum up from to , then we successfully get Eq.(35).
Derivation of Eq.(36)
The derivation of Eq.(36) is relatively simple. We just focus on , and combine the same items will give us correct coefficient which is . Then we sum up from to , and we get Eq.(36). See Wikipedia for more details about Abel transformation.
Why Long-term Decay?
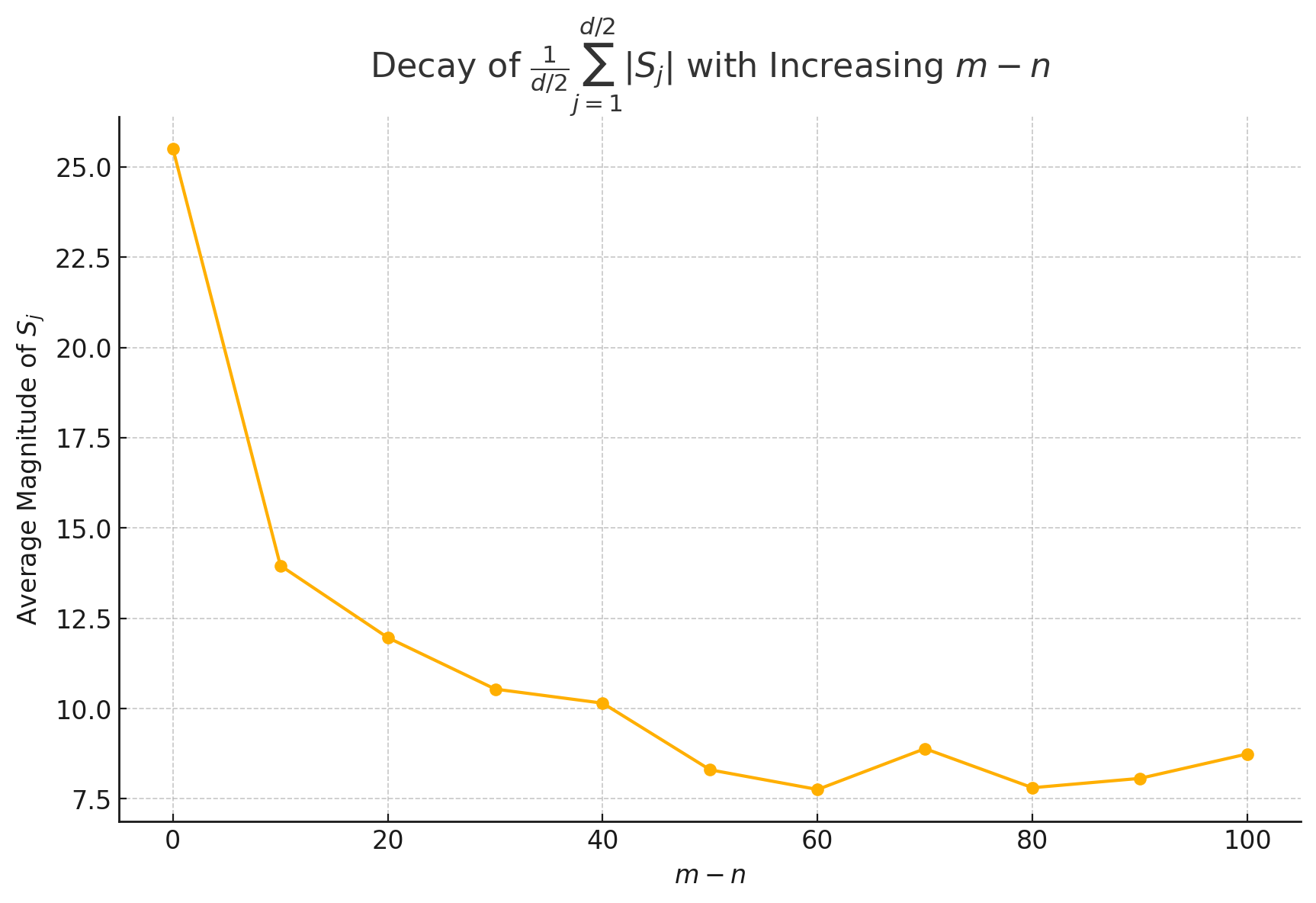
Well, then we arrive at the most important part, we try to understand why the value of decay with the relative distance increases by setting , where . This property could also be described as "the closer token gets more attention: the current token tends to pay more attention to the token that has a smaller relative distance", as discussed in Sec.4 of this paper4.
It's acutally very hard to analyze by taking derivative of , since we cannot easily find the analytical solution of.
One intuitive way to understand is to take the sum of as walking on a plane, which is the geometric meaning of adding two vectors. Apparently, when is close to zero, then we almost walking in a constant direction, which makes the sum of large. However, when is large, then the sum of will be small, since we are walking in different directions, with the worst case where we are walking in a circle.
The Concept of Phase Cancellation
Phase cancellation occurs when complex exponentials (vectors on the unit circle in the complex plane) with differing directions are summed together. The result can be a vector with a smaller magnitude than the individual vectors due to the geometric addition properties of complex numbers.
The Sum
Recall: with .
Examining the Phases
Distribution of Phases:
- The phases for each term in the sum depend on both and .
- As increases, the value of changes more rapidly due to the exponential nature of .
- For a fixed large , the phases effectively "scan" a broader range of angles on the unit circle as varies.
Uniform Distribution Assumption:
- If is sufficiently large and ranges over a significant interval, can cover the interval multiple times, depending on , effectively randomizing the phase angles.
- Under this assumption, the phases of the terms in can be seen as being uniformly distributed across .
Illustrating Cancellation
Cancellation Through Averaging:
- If the phases of are uniformly distributed or nearly so, the expected value of their sum approaches zero:
- Intuitively speaking, over is zero because for every vector, there is another vector pointing in the opposite direction, cancelling out.
Expected Magnitude with High Variability:
- While the average expected value is zero, individual realizations of can vary widely, typically resulting in smaller magnitudes as more vectors are added due to increasing likelihood of opposite directions.
- The more terms added (i.e., larger ), the greater the potential for cancellation, especially when provides a full or multiple rotations around the circle.
Surveying
1.The Influence of Base Choice on Long-term Decay
For same and , larger base will make the smaller. According to the blog here3, too small base (e.g. 1) will completely destroy the long-term decay property, while too large base will also decrease the long-term decay property. However, it's argued in aother work that to achieve longer context we need to have larger base4, more detailed results from this paper are illustrated by this table:
Long-term Decay of the Ability to Attend More to Similar Tokens than Random Tokens
Theorem4: Assuming that the components of query and key are independent and identically distributed, their standard deviations are denoted as . The key is a token similar to the query, where is a random variable with a mean of 0 . Then we have:
The perplexity cannot be used to evaluate long context capabilities
As indicated in 4, perplexity is not a good metric to evaluate the long context capabilities of a model. In Long-Eval bench, a model with small perplexity could have very low accuracy.
Desserts
Jianlin Su is a very talented guy, his Blogs are all very insightful. Among his numerous blogs, a series called "To upgrade Transformer" (Transformer 升级之路) really deserve an In-depth reading. Here I curate a list, since the search engine in the blog website seems not to work well.
Transformer 升级之路:2、博采众长的旋转式位置编码
- This blog introduces RoPE.
Transformer升级之路:4、二维位置的旋转式位置编码
- This blog introduces 2D RoPE, which could be applied in ViT.
Transformer 升级之路:7、长度外推性与局部注意力
Transformer 升级之路:9、一种全局长度外推的新思路
Transformer 升级之路:10、RoPE 是一种 β 进制编码
Transformer升级之路:17、多模态位置编码的简单思考
Transformer 升级之路:18、RoPE 的底数选择原则
Still updating.....
- Su, Jianlin, et al. "Roformer: Enhanced transformer with rotary position embedding." Neurocomputing 568 (2024): 127063.↩
- 苏剑林. (Mar. 23, 2021). 《Transformer 升级之路:2、博采众长的旋转式位置编码 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/8265↩
- Men, Xin, et al. "Base of RoPE Bounds Context Length." arXiv preprint arXiv:2405.14591 (2024).↩
- https://clvsit.github.io/RoPE-%E7%9B%B8%E5%AF%B9%E4%BD%8D%E7%BD%AE%E7%BC%96%E7%A0%81%E8%A7%A3%E8%AF%BB%E4%B8%8E%E5%A4%96%E6%8E%A8%E6%80%A7%E7%A0%94%E7%A9%B6/↩