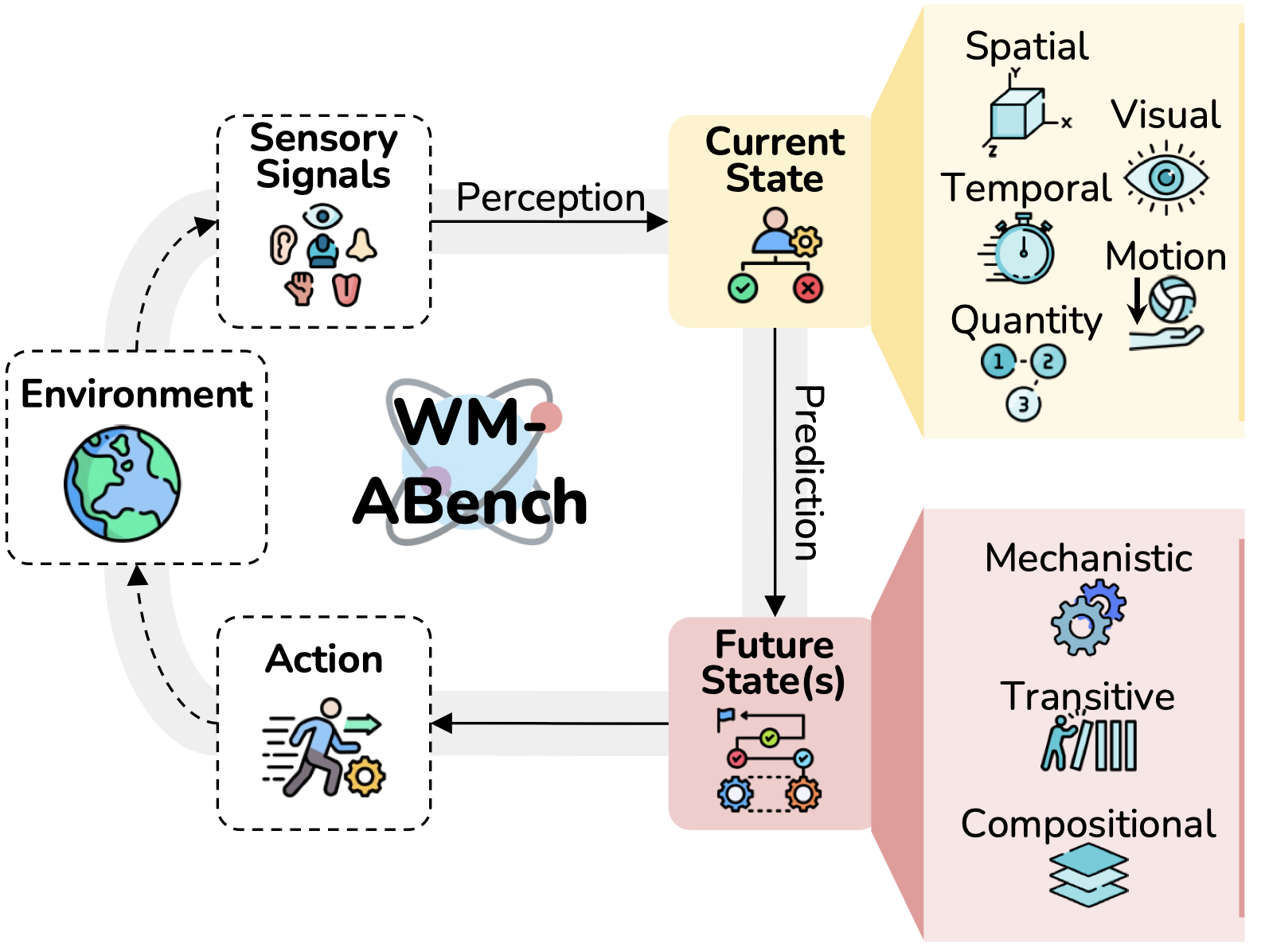
This paper evaluates whether modern Vision-Language Models (VLMs) like GPT-4o and Gemini can act as internal world models (WMs)—systems that understand and predict the world.
A benchmark exploring the performance of LLM Agents on detecting issues in datasets hosted on popular platforms.