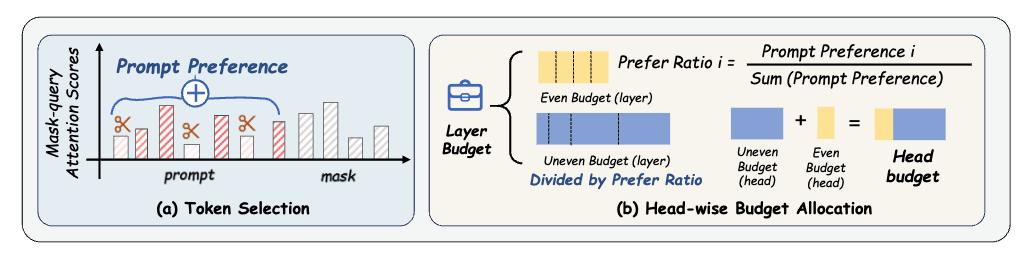
MaskKV exploits mask-token attention signals to evict low-utility KV pairs in diffusion LLMs, shrinking cache budgets while preserving long-context accuracy and increasing throughput.
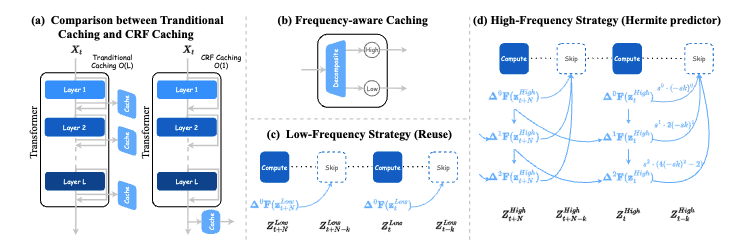
FreqCa accelerates diffusion models by analyzing frequency dynamics of features across timesteps, reusing low-frequency components and interpolating high-frequency ones with great memory reduction.