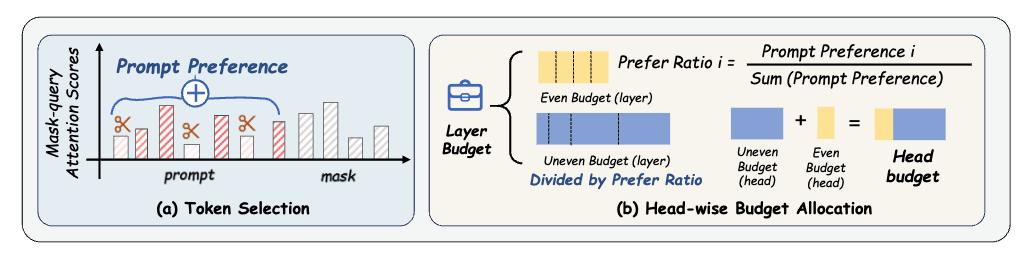
MaskKV exploits mask-token attention signals to evict low-utility KV pairs in diffusion LLMs, shrinking cache budgets while preserving long-context accuracy and increasing throughput.
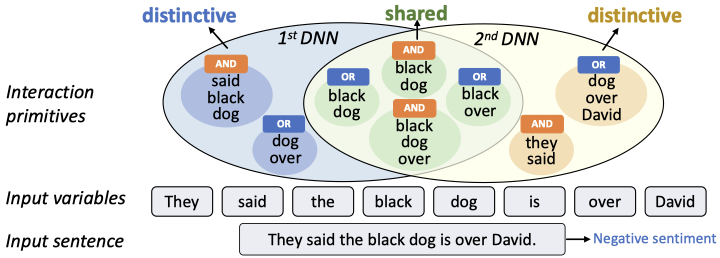
Given different DNNs trained for the same task, developed a new method to extract interactions that are shared by these DNNs. Experiments show that the extracted interactions can better reflect common ...